Регулярные выражения в Таблицах Google. Синтаксис RE2 в примерах и задачах
Введение в RE2 для формул в Таблицах Google.
Все примеры для этой статьи, и даже больше, специально собраны в одном файле, ссылку на который можно найти ниже. Таблица с примерами разработана таким образом, чтобы ее можно было наполнять новыми примерами и лайфхаками. Поэтому вместо копии рекомендуется добавить ее к себе на Диск
Регулярные выражения
Известно, что регулярные выражения уже плотно вошли в нашу жизнь. И не надо быть программистом, чтобы знать, что их лучше знать.
В формулах Таблиц Google широко используется формальный язык поиска и осуществления манипуляций с подстроками в тексте. Проще говоря, регулярные выражения . Эти выражения имеют синтаксис из библиотеки RE2 .
Вообще, регулярное выражение - это строка, которая указывает на некоторую группу строк, которым оно, регулярное выражение, соответствет. Например, выражению арбуз соответствует строка “арбуз”, а выражению [а-я]+з - любая строка, которая содержит один или более символов русского алфавита и заканчивается на букву “з”, это и “арбуз”, и “заказ”, и “порез” и т.д.
Что это дает?
Зная регулярное выражение можно:
- Проверить наличие подстроки в строке
- Выбрать или посчитать изначально неопределенное количество строк, соответствующих регулярному выражению
- Произвести подстановку или замену одних символов на другие, одну группу символов на другую
Основные формулы, которые используют регулярные выражения:
- REGEXMATCH - проверяет соответствие строки заданному регулярному выражению
- REGEXEXTRACT - пытается извлечь подстроку, соответствующую регулярному выражению
- REGEXREPLACE - заменяет строки согласно регулярному выражению
RE2
Safety is RE2’s raison d’être.
Из описания , RE2 - это быстрая, безопасная, ориентированная на потоки альтернатива механизмам регулярных выражений, например, используемым в PCRE, Perl и Python. Написана на C++.
Библиотека базируется на абстракции детерминированных конечных автоматов. RE2 гарантирует линейную скорость выполнения поиска и ограниченное использование стека.
Синтаксис регулярных выражений может отличаться, поэтому принципиально говорить о том, какая программа используется для их реализации.
Синтаксис
Различают элементы: одиночный символ , составные конструкции , конструкции повторения , [группировка СКОРО!], [флаг СКОРО!], [пустая строка СКОРО!], [управляющая последовательность СКОРО!], символьный класс , именованный символьный класс , символьный класс Perl , символьный класс ASCII , символьный класс Unicode .
Все элементы можно считать директивами или управляющими конструкциями.
Нет смысла запоминать все элементы. Есть смысл понимать принципы работы тех или иных конструкций.
Кострукция “одиночный символ”
Указывает на единичный символ в строке.
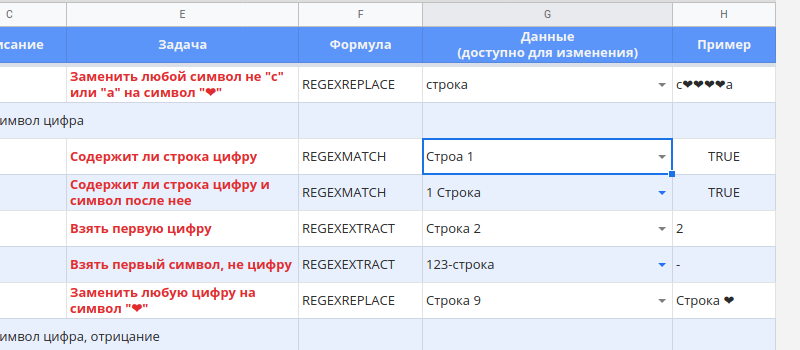
.- вообще любой символ[xyz]- один из перечисленных в квадратных скобках[^xyz]- любой один не из перечисленных в квадратных скобках\d- любая цифра\D- любая не цифра[[:alpha:]]- любой символ ASCII[[:^alpha:]]- любой символ не ASCII
Полный список примеров в Таблице примеры - одиночный символ .
Важным стоит отметить решение следующих задач
Проверка на пустую строку
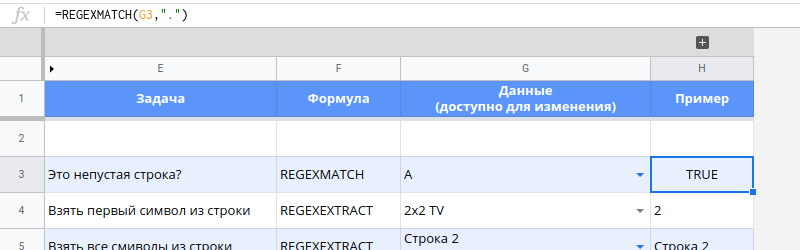
=REGEXMATCH(G3,".")
Замена каждого символа в строке
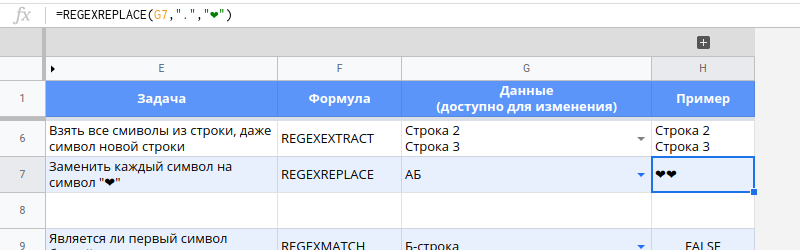
=REGEXREPLACE(G7,".","❤")
Проверка на определенный набор символов, например, на гласные
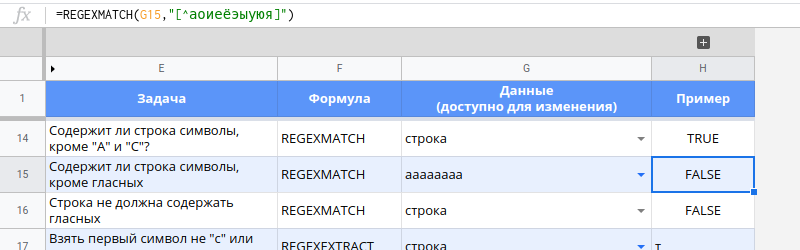
=REGEXMATCH(G15,"[^аоиеёэыуюя]")
Составные конструкции
Понятно, что работать с одиночными символами можно, но далеко не все реализуемо. На помощь приходят составные констукции
xy- за “x” обязательно должен следовать “y”, или строка не будет соответствовать выражению.x|y- за “x” обязательно должен следовать “y”, или строка не будет соответствовать выражению.
Полный список примеров в Таблице примеры - составные конструкции .
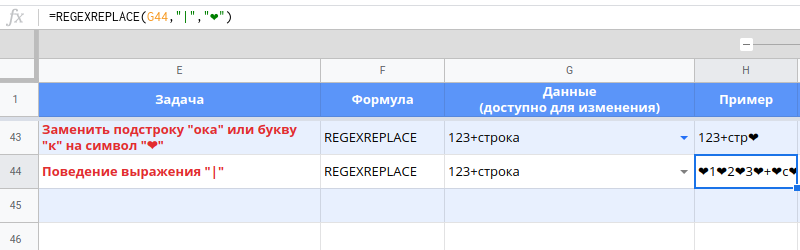
Важным стоит отметить поведение одиночного символа "|" в виде регулярного выражения. В качестве директивы он ничего не значит и предлагает выбрать “ничего” или “ничего”. Что, довольно интересно. Например, посмотрите пример замены "стр|" в примерах
Конструкции повторения
Особое место в синтаксисе регулярных выражений занимают конструкции поторения. Вероятно, потому что это самый частый способ указания на последовательности символов
x+- подряд идет не менее одного символа, предпочтение большинствуx*- подряд идет ноль или более символов, предпочтение большинствуx?- может присутствовать один символ или не быть вообщеx{n,m}- может присутствовать от n до m подряд идущих символов, предпочтение большинствуx{n,}- может присутствовать от n и более подряд идущих символов, предпочтение большинствуx{n}- может присутствовать только n подряд идущих символовx+?- подряд идет не менее одного символа, предпочтение меньшенству, нежадный поискx*?- подряд идет ноль или более символов, предпочтение меньшенству, нежадный поискx??- может присутствовать один символ или не быть вообще, предпочтение ничемуx{n,m}?- может присутствовать от n до m подряд идущих символов, предпочтение меньшенству, нежадный поискx{n,}?- может присутствовать от n и более подряд идущих символов, предпочтение меньшенству, нежадный поискx{n}?- может присутствовать только n подряд идущих символов
Список примеров в Таблице примеры - конструкции повторения
Ограничение реализации: конструкции x{n,m}, x{n,} и x{n} отклоняют выражения, которые создают минимальное или максимальное количество повторений выше 1000 раз. Неограниченные повторения не подпадают под это ограничение. Для Таблиц размер последовательности ограничен 32000 символами.
Принципиальное отличие конструкций со знаками * и + в том, что они не ограничивают длину повторений, кроме начального размера: нет повторений в случае со * и одино повторение при +.
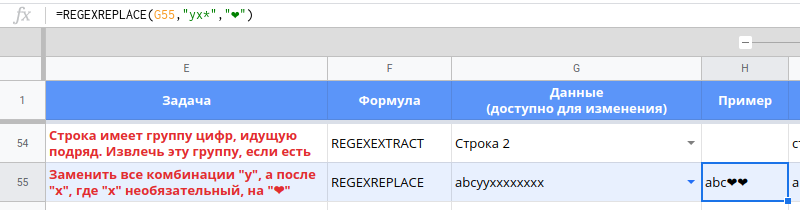
Важно отметить, как решается задача заменить все комбинации "yx", где "x" необязательный, на "❤", выражение yx*. Если "y" встречается подряд больше одного раза, то произойдет замена только "y", и только потом "yx". В строке "abcyyxxxxxxxx" будет заменен первый "y", а потом "yxxxxxxxx", вернет "abc❤❤".
Классы
Классы - условные обзначения тех или иных групп символов.
.- обозначение класса все символы\d,\D,\s,\S,\w,\W- управляющие классы Perl. Это означает, что регулярное выражение может быть использовано и в других, не RE2, программах. В основном работают или ссылаются на символы[[:alnum:]],[[:alpha:]],[[:ascii:]]и т.д. - классу принадлежат только символы ASCII , либо все, либо определенные группы- Классу символов Юникод принадлежит большая группа символов стандарта Юникод
- Класс именованных групп и класс символов Vim пересекаются и в основном повторяют классы Perl, тем самым расширяя возможности выражений за набор символов ASCII .
Классические задачи
Разбить строку посимвольно
Требуется разбить строку на символы. Например, 123.
Первое, что приходит на ум - это формула SPLIT .
- Пусть
A2- ячейка, которая содержит значение. - Приведем к строке
TO_TEXT(A2) - Добавим вокруг каждого символа символ “❤”
REGEXREPLACE(TO_TEXT(A2),"|","❤"). Вывод❤1❤2❤3❤ - Разобъем на массив
SPLIT(REGEXREPLACE(TO_TEXT(A2),"|","❤"),"❤")

=SPLIT(REGEXREPLACE(TO_TEXT(A2),"|","❤"),"❤")
Другим решением является использование свойства формулы REGEXEXTRACT - вывод групп в массив. Необходимо создать в регулярном выражении столько групп, сколько символов в строке

=REGEXEXTRACT(A3,REPT("(.)",LEN(A3)))
Еще подобные задачи в примере .
Ограничения
Особых ограничений и недостатков RE2 не имеет. Но существуют типы задач, которые эта билиотека без внешнего кода решить не может.
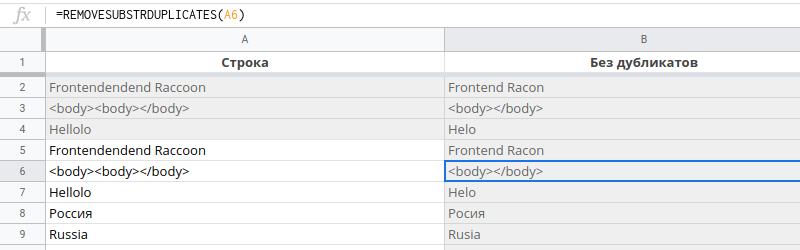
Задача на удаление повторов
Не решается формулами
Положим, у нас есть строка "<body><body></body>". Из спецификации языка HTML известно, что тег body может присутствавать в документе только однажды. Очевидно, что отдно из "<body>" лишнее.
Элегатно решить эту задачу можно через регулярные выражения, если обратиться к найденной подстроке тут же в регулярном выражении.
- И так. Найдем какую-то строку
.. - Хм, пусть символов будет один или больше
.+. - Ок. Теперь запомним ее
(.+). - Магия на следующем шаге.
- Обратимся к запомненному элементу
(.+)\1. - Если этих элементов больше 2, тогда учтем и это
(.+)\1+.
Ближайшая комбинация, которая удовлетворит этому выражению - это строка "<body><body>".
Повторюсь. Эту задачу нельзя решить формулой.
Скрипт для пользовательской функции может иметь вид
/**
* Удаляет повторы в строках
*
* @param {строка} string Строка для обработки
* @customfunction
*/
function REMOVESUBSTRDUPLICATES(string) {
var patt = /(.+)\1+/g;
var res = string;
var acc;
while (acc !== res) {
acc = res;
res = res.replace(/(.+)\1+/g, '$1');
}
return res;
}
Заключение
Скоро!
Ссылки
- Регулярные выражения
- Google справка “Поиск и замена текста ”
- Символы ASCII
- Юникод Юникод
- Примеры формул в Таблице
[]:/img/article/google-sheets-regexp-re2-syntax_01.png []:/img/article/google-sheets-regexp-re2-syntax_01.png
Обсудите с предпринимателями
Присоединяйтесь к Telegram-чату — здесь предприниматели обсуждают автоматизацию, AI-агентов и рост бизнеса.